When to Use Langfuse, LangSmith, or variA/Bly: Choosing Your LLMOps Stack in 2026
Langfuse, LangSmith, and variA/Bly all show up in the same "which LLMOps tool should I use" conversations — but they answer different questions. A practical, honest comparison with feature matrix, methodology breakdown, and a decision tree.
If you've been building production AI for any meaningful period, you've heard the same three names come up in every "what should I use?" conversation: Langfuse, LangSmith, and increasingly variA/Bly.
They sound competitive. They're not — at least not in the way most comparison posts suggest. The three tools sit on different parts of the LLMOps map, and the question worth asking isn't "which one wins" but "which combination do I actually need?"
This post unpacks where each tool fits, where they overlap, and how to pick the right stack for your team.
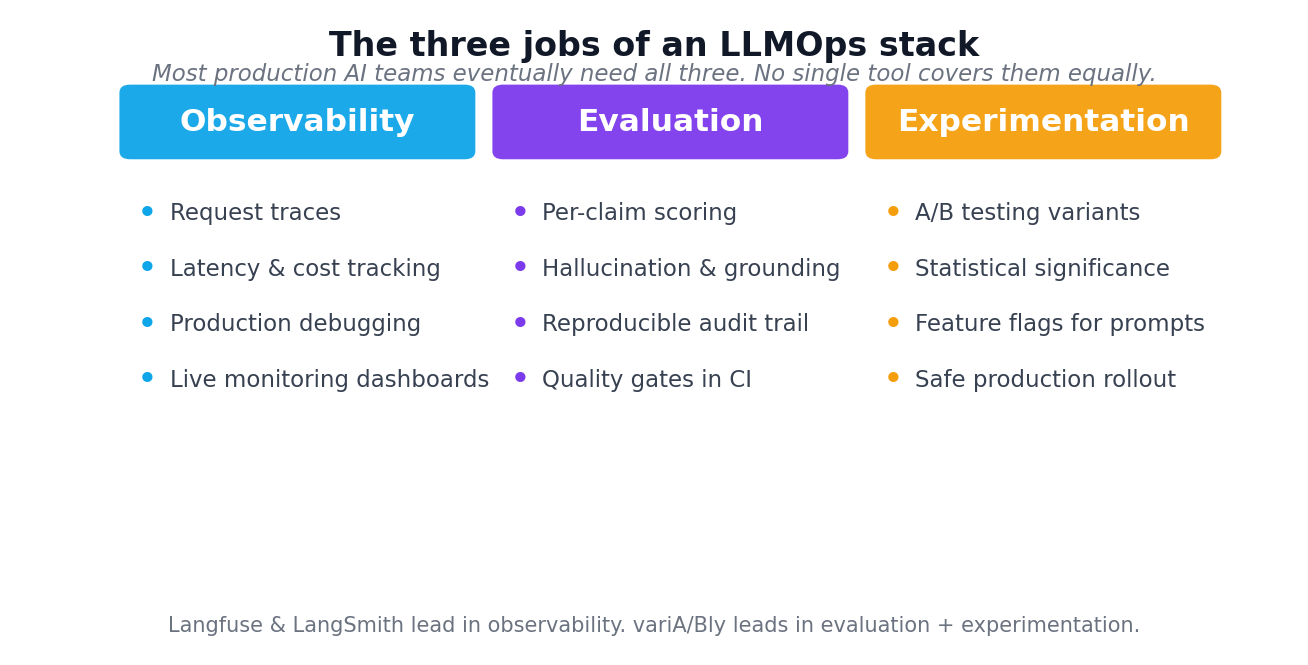
TL;DR — what each tool actually does
- Langfuse — open-source observability platform. Traces, latency dashboards, debug-friendly UI. Self-hostable. Eval features added later, all LLM-as-judge based.
- LangSmith — LangChain's first-party tracing + eval product. Closed source. Best DX if your stack is already LangChain-heavy. Eval features also LLM-as-judge.
- variA/Bly — evaluation-first platform with claim-level grounding, deterministic scoring, and built-in experimentation (A/B testing + feature flags for prompts). Hosted-only.
These are not one-for-one substitutes. Most mature production AI teams end up running observability and evaluation as separate concerns — the way most data teams run Datadog and dbt without forcing them into a single tool.
What each tool was built to do
Langfuse — observability for self-hosters
Langfuse was built to be the open-source answer to LangSmith. SDK, traces, dashboards, prompt management — all under MIT license, all self-hostable. If your security team has banned hosted LLMOps tools or you need full data residency, Langfuse is the strongest option in the category.
The eval features came later, and they're LLM-as-judge based. That means they share the methodology trade-offs you'd find in RAGAS or DeepEval: non-deterministic scores, token-cost surcharge per evaluation, sensitivity to judge-model drift.
Best for: teams that want OSS, self-hostable observability and are okay running a separate tool for deeper evaluation.
LangSmith — tight LangChain DX
LangSmith ships from LangChain, the company. If you're using LangChain or LangGraph already, LangSmith's tracing is essentially free — drop in two lines and traces start flowing. The dashboards are polished, the eval-set workflow is clean, and the team behind it iterates fast.
Like Langfuse, the eval side uses LLM-as-judge methodology. Custom evaluators are supported, but the defaults are judge-based.
Best for: teams already deeply on the LangChain stack who want tracing and eval in a single product, and are comfortable with closed source + hosted.
variA/Bly — deterministic evaluation + experimentation
variA/Bly is built around a different question: not "what did my LLM do" (observability) but "how good was the output, exactly, in a way I can defend in an audit later" (evaluation).
The scoring pipeline doesn't call an LLM to judge. It runs deterministic algorithms — Natural Language Inference models for grounding, embedding similarity for retrieval relevance, rule-driven claim-level decomposition, and domain-routed models for clinical, legal, and finance text. Same input, same score, every run.
On top of that sits an experimentation layer: A/B testing on production traffic, statistical significance gating, and feature flags for prompts so you can roll out LLM changes gradually instead of all at once.
Best for: teams that need audit-grade evaluation (regulated industries, compliance-driven verticals) or want statistical experimentation built into the eval surface.
Feature parity at a glance
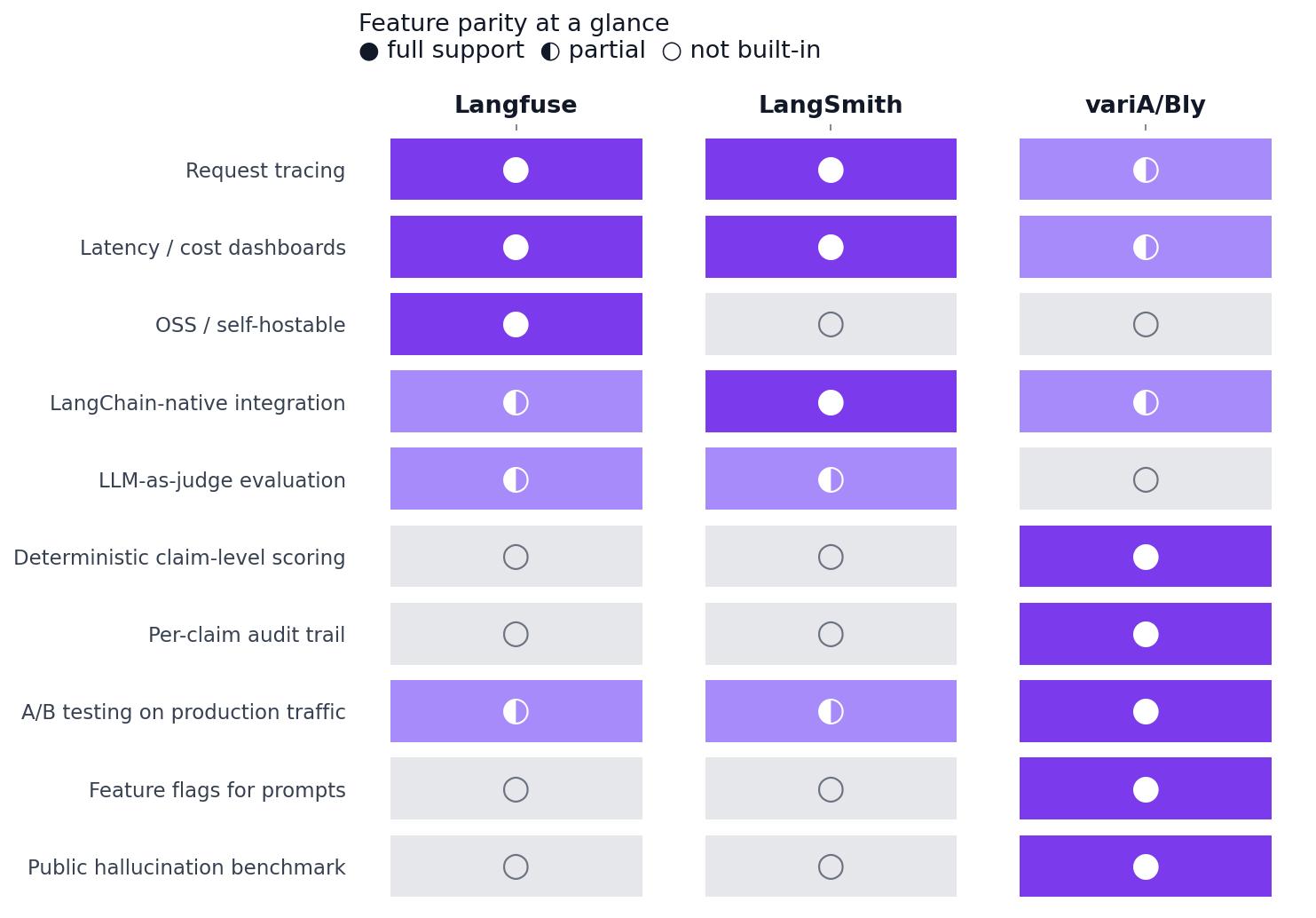
A few honest observations from the matrix:
- Langfuse owns OSS. Neither LangSmith nor variA/Bly is self-hostable. If that's a hard requirement, Langfuse is your pick — full stop.
- LangSmith owns LangChain integration. Of course it does — same parent company. The integration is friction-free in a way the others can't match.
- variA/Bly is the only one with built-in deterministic scoring and a per-claim audit trail. Not a value judgment — it's a methodology choice. None of the tools are wrong; they just answer different questions.
The evaluation methodology question
This is where the comparison shifts from features to how evaluation actually works under the hood.
Langfuse and LangSmith both ship LLM-as-judge evaluation. You hand them a response, a reference, and a metric definition, and they call an LLM to score it. This works fine for many use cases — open-ended creative judgment, vibes-checks, multi-turn coherence where there isn't a single correct answer.
But LLM-as-judge has three known failure modes that matter for production quality gates:
1. Score variance — same input, different scores
Run the same evaluation twice, get different scores. This happens even at temperature 0 because of subtle non-determinism in modern LLMs — which is why OpenAI added the seed parameter and system_fingerprint field specifically to give developers reproducibility hooks. The variance is usually small, occasionally big enough to flip pass/fail gates.
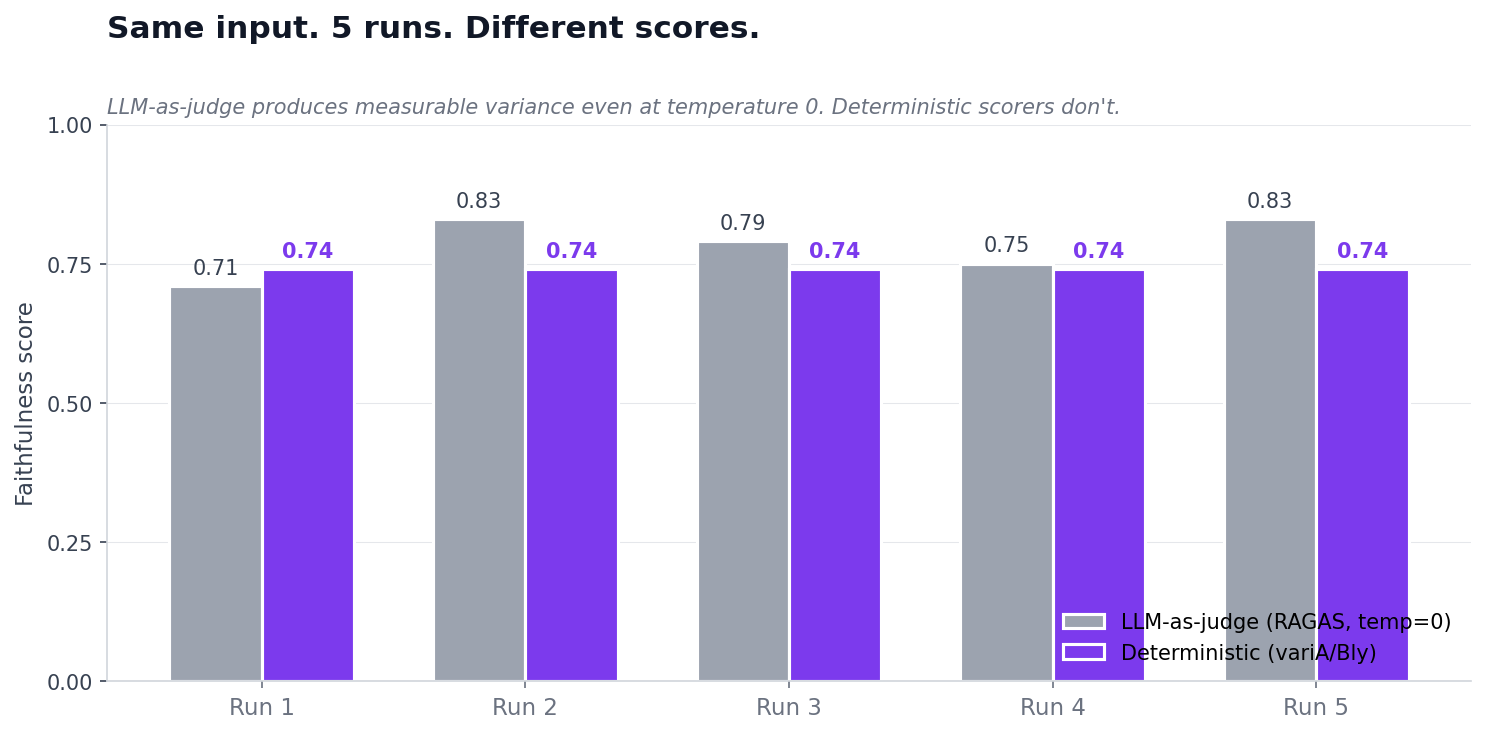
The variance has downstream consequences: A/B significance math assumes a stable measurement instrument; regression detection assumes the scorer hasn't moved; audit trails assume a score reproduces. None of those assumptions hold cleanly with LLM-as-judge. We unpacked this in more detail here.
2. Token-cost surcharge that scales with prompt size
Every LLM-as-judge evaluation is another LLM call. In production, that judge is usually a stronger (and 3–4× more expensive per token) model than the one being judged. At 10K evals per month with a Sonnet-class judge, the evaluation bill alone can exceed your inference bill. The math is brutal at scale — we walked through it here.
The pricing impact applies whether you're using RAGAS, DeepEval, Langfuse's eval features, or LangSmith's. It's a property of the methodology, not of any specific vendor.
3. Methodology gaps on technical content
When the response includes claims to verify against retrieved context — RAG, clinical, legal — LLM-as-judge tends to over-approve. It pattern-matches on plausibility instead of grounding. The public benchmark numbers tell the story:
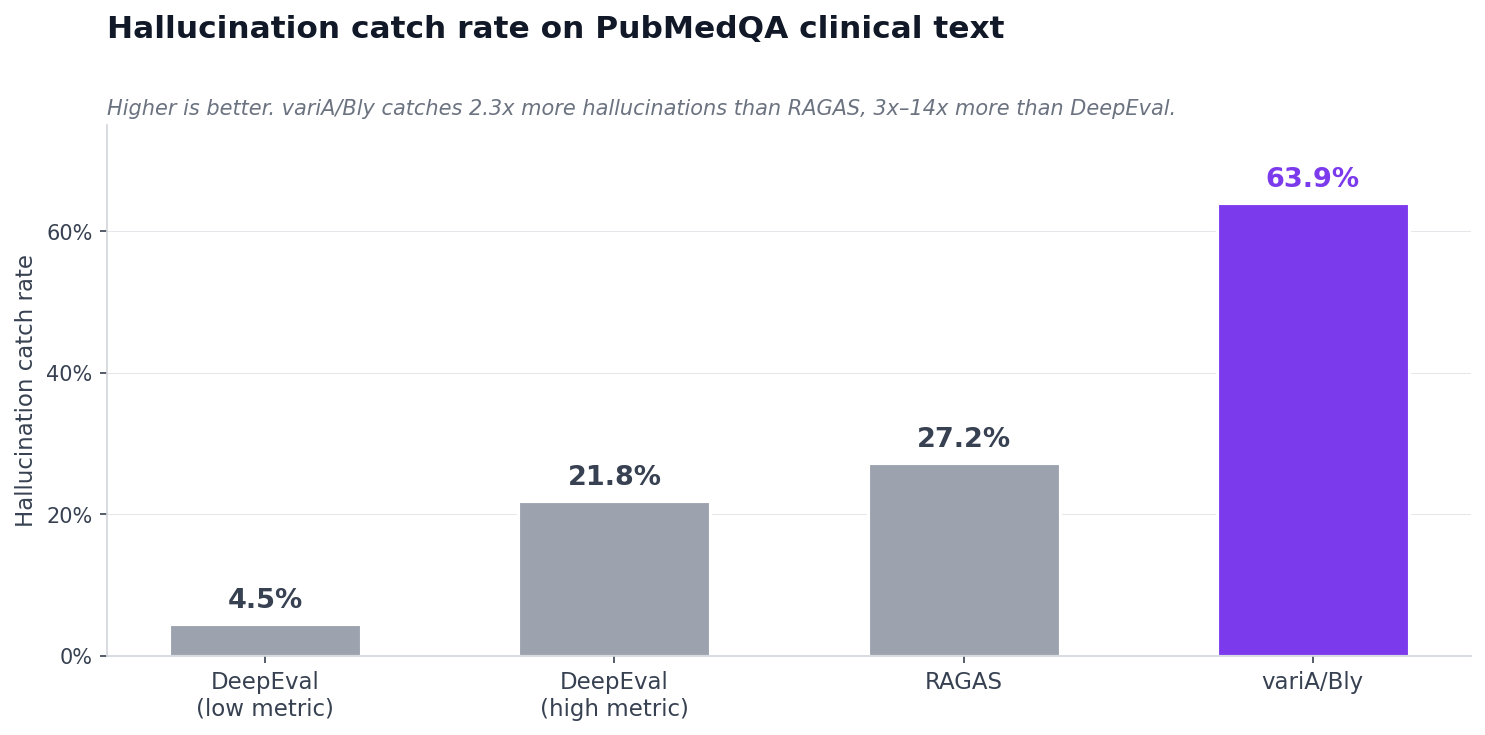
variA/Bly's claim-level deterministic methodology catches 2–14× more hallucinations than LLM-as-judge tools on clinical text (PubMedQA, n=500). The Apache-2.0 benchmark scripts are public — you can run the math yourself.
This isn't a knock on Langfuse or LangSmith. Their LLM-as-judge eval is fine for the use cases it's designed for. It just isn't the right tool for production gates where the answer should exist and the score should reflect it.
Where each tool sits on the map

The most mature teams converge on the upper-right corner — heavy observability and heavy evaluation. They don't try to force one tool to do both.
A simple decision tree
Pick Langfuse if:
- You need OSS or self-hostable observability for compliance / data residency
- Your eval needs are basic (vibes-checks, prompt-management workflows)
- You're comfortable wiring up a separate eval tool later
Pick LangSmith if:
- You're already on LangChain / LangGraph and want the tightest possible integration
- You want tracing + basic eval in a single product
- You're okay with closed source, hosted-only
Pick variA/Bly if:
- You're shipping AI in a regulated domain (clinical, legal, financial) and need an audit-defensible eval pipeline
- You want statistical A/B testing and feature flags built into the eval surface
- You need scores that reproduce byte-for-byte (CI gates, regression detection, compliance)
- You're comfortable with hosted-only
Run two of them together if:
- You need production observability AND deep evaluation (the common case)
- A common pairing: Langfuse (or LangSmith) for traces + variA/Bly for scoring + experimentation
- The tools don't conflict — different SDKs, different data, different jobs
Pricing at a glance
| Tool | Pricing model | Where it gets expensive |
|---|---|---|
| Langfuse | OSS free / hosted from $59/mo | LLM-as-judge token surcharge once you turn on evals |
| LangSmith | Hosted, usage-based | Trace volume + LLM-as-judge tokens for evals |
| variA/Bly | Subscription + per-evaluation SEU ($0.012–$0.015) | Volume of evaluations only — bill doesn't move with prompt size |
More on variA/Bly's SEU pricing.
The complementary pattern
The framing most posts get wrong is treating "Langfuse vs LangSmith vs variA/Bly" as if you have to pick one. Most teams in production are running an observability tool and an evaluation tool together — because they answer different questions:
- "Was the request slow / did it fail / where did latency go?" → observability
- "Was the response good / grounded / hallucination-free?" → evaluation
- "Should we ship variant B over variant A?" → experimentation
Try to make one tool do all three and you compromise on each. Use the right tool for each job and you get a stack you can actually defend six months in, when something breaks and you're trying to figure out which layer is the problem.
See variA/Bly's evaluation methodology, the public benchmark repo, or pricing.
Want this kind of evaluation for your RAG system?
Talk to us